










Das jüngste Papier von Flare Research Veröffentlichung stellt einen neuen Ansatz für künstliche Intelligenz (KI) vor, bei dem die Kombination von KI mit Blockchain zu einer sichereren und genaueren KI führt.
Das Konsenslernen (CL) ermöglicht kollaborative KI in einem breiten Spektrum von Anwendungen und damit die Entwicklung genauerer und robusterer KI-Modelle. CL eignet sich besonders für die KI-Integration in datenintensiven Sektoren wie dem Gesundheits- oder Finanzwesen. Dadurch werden Entscheidungsprozesse verbessert und die allgemeine betriebliche Leistung und Effizienz gesteigert, was wiederum zu niedrigeren Kosten für Dienstleistungen für den Endverbraucher führen kann. Dies kann unter anderem zu deutlich besseren Ergebnissen in der Patientenversorgung, genaueren Finanzanalysen oder einer verbesserten Betrugsaufdeckung führen. Im Gegensatz zu den meisten bestehenden Implementierungen von KI und Blockchain, die den Zugriff auf zentralisiertes maschinelles Lernen (ML) über die Blockchain ermöglichen, nutzt CL die Blockchain zur Erstellung dezentraler KI-Modelle.
Motivationen
In den letzten Jahren hat sich der Schwerpunkt zunehmend auf verteilte Umgebungen verlagert, in denen Daten und Rechenressourcen auf mehrere Geräte verteilt sind. Diese Verlagerung wird durch die Anforderungen moderner Basismodelle, wie z. B. große Sprachmodelle und Computer-Vision-Modelle, ausgelöst, die erhebliche Datenmengen für die Verarbeitung erfordern. In diesem verteilten, aber immer noch zentralisierten Umfeld wird die Dezentralisierung zu einem grundlegenden Erfordernis, das durch mehrere Hauptmotivationen angetrieben wird.
Zentralisierte Methoden bergen inhärente Risiken, da sie sich auf eine einzige vertrauenswürdige Partei stützen, was ihre Verwendung hauptsächlich auf einzelne Unternehmen beschränkt und ihre breitere Anwendung einschränkt. Darüber hinaus erhöhen diese Architekturen nicht nur die Anfälligkeit für potenzielle Angriffe oder Systemausfälle, sondern werfen auch Bedenken hinsichtlich des Datenschutzes und der Sicherheit auf. Umgekehrt bieten dezentrale Methoden einen entscheidenden Vorteil: Sie ermöglichen es den Nutzern, personalisierte lokale Modelle zu entwickeln, die auf ihre spezifischen Anforderungen und Präferenzen zugeschnitten sind, während zentralisierten Ansätzen oft die für eine solche Anpassung erforderliche Flexibilität fehlt. Inmitten dieser Einschränkungen erweist sich das Konsenslernen als eine dezentrale ML-Lösung, die eine größere Widerstandsfähigkeit, Privatsphäre und Anpassungsfähigkeit bietet und gleichzeitig die mit der Zentralisierung verbundenen Risiken mindert.
Vorteile des Konsenslernens
Konsensprotokolle sind für die Sicherheit dezentraler Ledger unerlässlich und schützen Blockchain-Netzwerke vor bösartigen Angriffen. Die Nutzung von Konsensmechanismen für KI hat viele Vorteile, von denen wir die folgenden hervorheben:
- Verbesserte Leistung. CL-Methoden profitieren von den Daten jedes einzelnen Teilnehmers des Ensembles, wodurch Verzerrungen reduziert und die Fähigkeit der Modelle zur Verallgemeinerung auf ungesehene Daten verbessert werden. CL kann auch zu einer genaueren KI im Vergleich zu zentralisierten Methoden führen, vor allem aufgrund der Fähigkeit der Blockchain, Anreize für die Zusammenarbeit zu schaffen, was zu einer größeren Fähigkeit führt, verschiedene Erkenntnisse aus verschiedenen Modellen zu kombinieren. Dies wird durch mehrere lokale Aggregationen erreicht, bei denen jeder Teilnehmer die Vorhersagen benachbarter Modelle bewertet und sie zur Verbesserung der Genauigkeit integriert. Dies ist einer der ersten Fälle, in denen KI aus der Blockchain-Integration erhebliche Vorteile ziehen kann.
- Sicherheit. Auch wenn böswillige Akteure versuchen, versteckte Ziele einzuführen, bleibt die Integrität der KI-Modelle aufgrund der eingebauten Sicherheitsmerkmale der Konsensmechanismen unangetastet. Dadurch wird sichergestellt, dass KI-Systeme keine absichtlichen schädlichen Vorhersagen oder unbeabsichtigte Ungenauigkeiten erzeugen, beides Markenzeichen böswilliger KI. Folglich geht CL auf ein wichtiges Anliegen der KI-Gemeinschaft ein, nämlich den Schutz der KI vor Ausnutzung für schädliche Zwecke. Durch die Wahrung der Integrität des kollaborativen Lernprozesses schafft CL mehr Vertrauen in KI-Systeme und ebnet den Weg für deren verantwortungsvollen und ethischen Einsatz.
- Schutz der Daten. Im CL werden weder die zugrunde liegenden Daten der Netzwerkteilnehmer noch ihre individuellen Modelle an irgendeiner Stelle weitergegeben. Tatsächlich gibt es keine böswilligen Angriffe auf das Netz, die die Vertraulichkeit der Daten gefährden könnten, da die Daten lokal gespeichert bleiben. Die Wahrung der Privatsphäre fördert nicht nur die Zusammenarbeit, sondern erhält auch die Wettbewerbsfähigkeit. In dieser Hinsicht ermöglicht CL die Monetarisierung von Daten durch KI, insbesondere bei sensiblen oder kommerziellen Daten, wie z. B. im Gesundheitswesen, und überwindet damit frühere Herausforderungen, die in zentralisierten Umgebungen auftreten.
- Vollständige Dezentralisierung. Daten und Rechenressourcen sind über ein Netzwerk von Teilnehmern verteilt, die miteinander kommunizieren, ohne sich auf einen einzigen zentralen Server zu verlassen. Die Notwendigkeit der Dezentralisierung ist in modernen ML-Anwendungen aufgrund des hohen Ressourcenbedarfs und der zunehmenden Komplexität der ML-Modelle deutlich erkennbar. Dezentrales ML erweist sich als geeignetere Lösung zur Wahrung des Datenschutzes und zur Gewährleistung der Sicherheit.
- Effizienz. Der Lernprozess hat eine geringe Latenzzeit und benötigt im Vergleich zu anderen modernen dezentralen ML-Methoden viel weniger Rechenzeit, Energie und Ressourcen. Dadurch eignet sich CL besonders für Echtzeitanwendungen, bei denen eine schnelle Entscheidungsfindung und eine effiziente Ressourcennutzung von größter Bedeutung sind.
Wie es funktioniert
Das Konsenslernen erweitert die Ensemble-Methoden um eine Kommunikationsphase, in der die Teilnehmer ihre (Modell-)Ergebnisse austauschen, bis eine Einigung erzielt wird. CL ist ein zweistufiger Prozess, der wie folgt implementiert werden kann:
- Individuelle Lernphase. Jeder Netzwerkteilnehmer entwickelt sein eigenes Modell auf der Grundlage seiner privaten Daten und anderer öffentlich verfügbarer Daten. Dies kann von der Erstellung eines Modells von Grund auf bis hin zur Verwendung großer, bereits trainierter Modelle und deren Feinabstimmung auf die eigenen Bedürfnisse reichen. Entscheidend ist, dass die Teilnehmer niemals sensible Informationen über ihre Daten oder ihr Modell weitergeben müssen. Sobald das Training abgeschlossen ist, bereiten die Teilnehmer ihre ersten Vorhersagen für einen Testdatensatz vor. Dabei kann es sich um einen Datensatz handeln, der über einen Smart Contract offengelegt wird, oder die Teilnehmer können neue Testdatenpunkte vorschlagen, zum Beispiel über einen Proof-of-Stake-Mechanismus.
- Kommunikationsphase. Die Teilnehmer übermitteln ihre ersten Vorhersagen innerhalb des Netzes nach einem Konsens-/Klatschprotokoll. Während dieses Austauschs aktualisieren die Teilnehmer laufend ihre Prognosen, um die Einschätzungen der anderen Netzwerkteilnehmer sowie das Vertrauen in ihre eigenen Prognosen zu berücksichtigen. Darüber hinaus kann ein Teilnehmer die Qualität der vom Rest des Netzes erhaltenen Vorhersagen überwachen und dies zur Verbesserung seiner Entscheidungsfindung nutzen. Am Ende dieser Phase einigen sich die Teilnehmer auf die Entscheidung, die sie angesichts der im Netz verfügbaren Informationen für optimal halten. Diese Phase wird dann für jeden neuen Dateninput wiederholt.
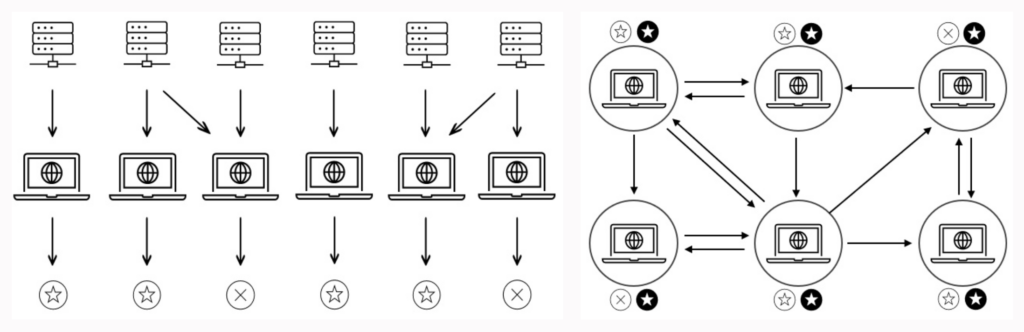
Bildunterschrift: Ein Beispiel dafür, wie CL bei einer binären Klassifizierungsaufgabe funktioniert. (a) In der ersten Phase entwickeln die Teilnehmer ihre eigenen Modelle auf der Grundlage ihrer eigenen Daten und möglicherweise anderer Daten, die von anderen Teilnehmern freiwillig zur Verfügung gestellt werden. Am Ende dieser Phase bestimmt jedes Modell eine erste Vorhersage (dargestellt durch die hohlen Kreise) für alle Eingaben des Testdatensatzes. (b) In der Kommunikationsphase tauschen die Teilnehmer ihre anfänglichen Vorhersagen aus und aktualisieren sie, bis sie sich schließlich auf eine einzige Ausgabe einigen (dargestellt durch die gefüllten Kreise). Diese Phase wird für alle neuen Dateneingaben wiederholt.
Streng genommen bezieht sich der oben beschriebene Algorithmus auf ein überwachtes ML-Szenario, d. h. auf eine Situation, in der die Trainingsdatensätze bereits beschriftet sind und der Algorithmus Vorhersagen für die Beschriftungen der neuen, ungesehenen Testdaten trifft. CL kann jedoch auch an selbstüberwachte oder unüberwachte ML-Probleme angepasst werden, bei denen die Teilnehmer nur Zugang zu teilweise oder vollständig unmarkierten Daten haben. Die Ziele dieser Methoden unterscheiden sich geringfügig, so dass die Teilnehmer in der individuellen Lernphase andere Techniken anwenden müssen. Nichtsdestotrotz würde die Kommunikationsphase ähnlich ablaufen wie die oben beschriebene.
Wie sich das Konsenslernen von anderen unterscheidet
Die Idee hinter CL besteht darin, Wissen (in Form von KI-Modellen) aus mehreren Quellen effizient zu kombinieren, ohne sensible oder wertvolle Informationen oder geistiges Eigentum zu teilen. Dieser Ansatz ist darauf ausgelegt, vertrauliche Informationen zu schützen und gleichzeitig die Widerstandsfähigkeit gegen potenzielle Risiken durch böswillige Organisationen zu gewährleisten. CL baut auf dem sehr erfolgreichen Paradigma des Ensemble-Lernens auf, das leistungsstarke Techniken für die Zusammenführung mehrerer Modelle in ein einziges Modell bietet. Ensemble-Methoden beruhen auf dem Prinzip der "Weisheit der Massen", bei dem das kollektive Wissen einer Menge genutzt wird, um das eines einzelnen Mitglieds zu übertreffen.
In den letzten Jahren sind mehrere Blockchain-Implementierungen von KI-Diensten aufgetaucht, die innovative Ansätze zur Integration von KI in dezentrale Netze zeigen. Bittensor beispielsweise erleichtert KI-Schlussfolgerungen (Modellausgabe) innerhalb seiner domänenspezifischen Teilnetze, indem es die Vorhersagen der "Miner" durch einen spieltheoretischen Mechanismus gewichtet. FLock.io bietet eine Plattform für föderiertes Lernen (eine andere Art des verteilten Lernens), allerdings mit einem zentralisierten Aggregator, der die Blockchain zur Validierung von Modellaktualisierungen und zur Belohnung der Teilnehmer nutzt. Ein weiteres Beispiel ist Ritual, das über sein Infernet-Protokoll effektiv einen Marktplatz für ML-Modelle betreibt, bei dem Anfragen zur Ausführung eines bestimmten Modells an den Modelleigentümer gesendet werden.
CL zeichnet sich durch seine besondere Aggregationsmethode aus, bei der die Vorhersagen der einzelnen Modelle ein sicheres Klatschprotokoll durchlaufen, um eine Einigung zu erzielen. CL nutzt die Blockchain, um dezentralisierte KI-Modelle zu erstellen, während bestehende Implementierungen den Zugriff auf zentralisierte KI über die Blockchain ermöglichen. Der Schwerpunkt liegt auf der Ermöglichung einer genaueren und sicheren KI durch Zusammenarbeit, während gleichzeitig Unternehmen, die über private, oft sensible Daten verfügen, die Möglichkeit haben, sich dem System anzuschließen, wobei die Vertraulichkeit ihrer Daten gewährleistet ist.
Zusammengefasst
Das Konsenslernen bietet eine bahnbrechende Möglichkeit, maschinelles Lernen direkt auf dezentralen Ledgern wie Blockchains zu implementieren. Mit dieser Initiative entsteht ein neuer Ansatz, bei dem die Blockchain-Technologie bestehende KI-Tools grundlegend verbessern kann. Dies eröffnet spannende Möglichkeiten für Innovation und sichere Zusammenarbeit in traditionell datensensiblen Sektoren wie dem Gesundheitswesen und schafft die Voraussetzungen für die Einführung von kollaborativen ML-Techniken. Darüber hinaus fördert die Widerstandsfähigkeit von KI-Methoden gegenüber bösartigen Faktoren das Vertrauen in KI-Systeme und stärkt deren Zuverlässigkeit und Integrität.